



“Hey, do you have any script to manage, resolve shortened URLs? There are plenty of shortened URLs these days and there have to be a way to see what’s hidden behind short URL!”
Colleague.
Intro
Recently I received that question from a collegue and I instantly replied that I don’t have such tool. It is unsafe to just put shortened URL in the web browser and hit enter. Short URL may point to some nasty things and your web browser would automatically download a file/open website content. So I advised my colleague to send HTTP request using HEAD method (using cURL for example) just to see what URL will be in a HTTP response headers (Location header). He could send HEAD requests until he receives 200 status code from a server – it would mean he reached his final destination.
After thinking a while I realized that is a good idea to implement above steps in Python – just as an exercise – I am aware of online tools capable of resolving shortened URLs (like https://www.expandurl.net/ )
Simple
I decided to use requests library. So if you want to follow along, make sure you have requests library installed.
> pip install --upgrade requestsWhen I develop python scripts, usually I do it line by line using ipython interpreter and after validation I put line of code to VSCode.
So lets start with import section. From requests library we need to import part of code responsible for sending HTTP request using HEAD method.
from requests import head
For this exercise I’ll use this URL: https://bit.ly/3xS4izz, which points (spoiler alert!) to this blog. Lets create a variable with our test shortened URL
URL = 'https://bit.ly/3xS4izz'
Now we have everything prepared to send HTTP request. That was quick, right?
Ok, now we will do two things in one line of code. We will create a variable and we will send HEAD request to our URL. The variable will hold a response received from a server. Lets be creative and name our variable response.
response = head(URL)
Now we recorded a response from a server in response variable. Did we received any content from a server? Let’s check in ipython:
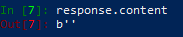
There is nothing! Why is that?! Because we sent HTTP request using HEAD method which mustn’t return any content. So all is OK.
If there is no content in a response, check headers – they should be there!

We have our headers. From headers we want to extract ‘Location’ header. It looks like response.headers returns a dictionary, let’s try response.headers[‘Location’] to extract value of ‘Location’ header:

Voilà! We could just add print(response.headers[‘Location’]) function to print output to the console and call it a day! This very simple, basic version of the script look like this:
from requests import head
URL = 'https://bit.ly/3xS4izz'
response = head(URL)
print(response.headers['Location'])
Less Simple But Still Simple
But did we really got a finall URL? http://firewallops.com will redirect us to https:// version and to /blog path.
As I wrote at the begining URL should be ‘probed’ with HEAD method util server returs 200 status code. And what status code we received using basic version of the script?:

It is 301, and we want to receive 200 status code. If there are be few redirects to the final URL we receive only the first one.
How to solve this? Each time after we send HEAD request we need to check what is a status code. If it is a code from 3xx family, we need to update our URL variable with value from ‘Location’ header and send request again. Python code:
if str(response.status_code).startswith('3'):
for k,v in r.headers.items():
if 'ocation' in k:
URL = v
response = head(URL)
First we convert status code to string (it is an integer by default) to be able to check if its value starts with ‘3’, which represents redirect action. Next we iterate over dictionary items. Because dictionary is built with Keys and Values we need to unpack them to the corresponding variables for further use. In the for loop we check ‘ocation’ string exist in dictionary key k (‘ocation’ and not ‘Location’ because some server implentations may return lowercase ‘location’). If there is a match we update our URL with value v. And we send new HEAD request to the new URL.
Lets add a case when we will receive 200 code and a case when status code will be something different:
if str(response.status_code).startswith('3'):
for k,v in r.headers.items():
if 'ocation' in k:
URL = v
response = head(URL)
elif r.status_code == 200:
print(URL)
else:
print('Different response code')
We need to wrap above code in while loop. With while loop, script will run until it finds 200 status code or error occurs. Ok, I mentioned error – we will wrap code responsible for sending request with try: except: blocks, to catch errors where ie. connection to server will timeout.
while True:
if str(response.status_code).startswith('3'):
for k,v in response.headers.items():
if 'ocation' in k:
URL = v
try:
response = head(URL)
except:
print('Ooopsss')
break
elif response.status_code == 200:
print(URL)
break
else:
print('Different response code')
break
So until now our script should look like this:
from requests import head
URL = 'https://bit.ly/3xS4izz'
response = head(URL)
while True:
if str(response.status_code).startswith('3'):
for k,v in response.headers.items():
if 'ocation' in k:
URL = v
try:
response = head(URL)
except:
print('Ooopsss')
break
elif response.status_code == 200:
print(URL)
break
else:
print('Different response code')
break
We need to safeguard our initial HEAD request with try: except: blocks. And when error occurs at this stage, we want to stop script execution with exit() function. But first we need to import it from sys library. Our updated import section and initial HEAD request should look like:
from requests import head
from sys import exit
URL = 'https://bit.ly/3xS4izz'
try:
response = head(URL)
except:
print('Oooops')
exit()
With above update, script should look like:
from requests import head
from sys import exit
URL = 'https://bit.ly/3xS4izz'
try:
response = head(URL)
except:
print('Oooops')
exit()
while True:
if str(response.status_code).startswith('3'):
for k,v in response.headers.items():
if 'ocation' in k:
URL = v
try:
response = head(URL)
except:
print('Ooopsss')
break
elif response.status_code == 200:
print(URL)
break
else:
print('Different response code')
break
Now it is a time to test our code in ipython:
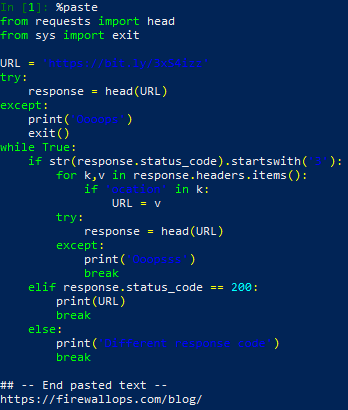
Yes! It is working with our URL… what about different URL? Do we have to edit the script each time we want to test different URL? Right now yes, but it is not an efficient way. Hmm let’s modify script to provide URL as an arguement. First we need to import argv from sys library. So updated import section should look like:
from requests import head
from sys import exit, argv
Now it is time to assign URL provided as an argument to the URL variable in the script. But first we have to check if argument has been assigned at all.
if len(argv) < 2:
print('Please provide a URL.')
exit()
len(argv) return length of argv list, so it checks the number of provided arguments and if less than two a label prints and script stops. Why 2?:

Now let’s take care of case when arguement has been provided. Let’s complete our if else statement:
if len(argv) < 2:
print('Please provide a URL.')
exit()
else:
URL = argv[1]
try:
response = head(URL)
except:
print('Oooops')
exit()
If we put together everything, the final version of our script should look like this:
from requests import head
from sys import exit, argv
if len(argv) < 2:
print('Please provide a URL.')
exit()
else:
URL = argv[1]
try:
response = head(URL)
except:
print('Oooops')
exit()
while True:
if str(response.status_code).startswith('3'):
for k,v in response.headers.items():
if 'ocation' in k:
URL = v
try:
response = head(URL)
except:
print('Ooopsss')
break
elif response.status_code == 200:
print(URL)
break
else:
print('Different response code')
break
Test Time
It is a time to test our script with arguments. No time to waste, vamos!
> python resolve-short-urls.py https://bit.ly/3xS4izzAbove command should print a URL of our blog.

What will happen if we provide non-existing domain? Script should print ‘Oooops’ and stop. Test:
> python resolve-short-urls.py http://i-dont-think-it-exists.do-you
And what will happen if we provide two legitimate URLs as arguments? Script will not take care of the second one, it will check only the first URL provided.
> python resolve-short-urls.py https://bit.ly/3xS4izz http://fox.com
Summary
Developing this script was fun (at least for me:D ). It shows how basic usage of requests library, how to send HTTP request using HEAD method, how to work with the response and build new requests based on the header value.
More python posts you can find under python category.
If you are reading this sentence, you probably reached to the end of this post. Thank you for your attention! Leave a comment if you like 😉
Krzysztof.